背景
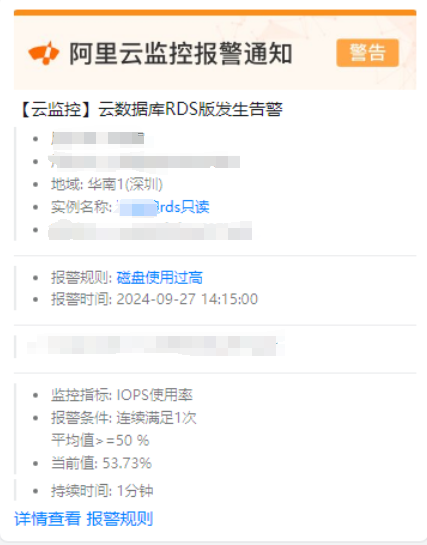
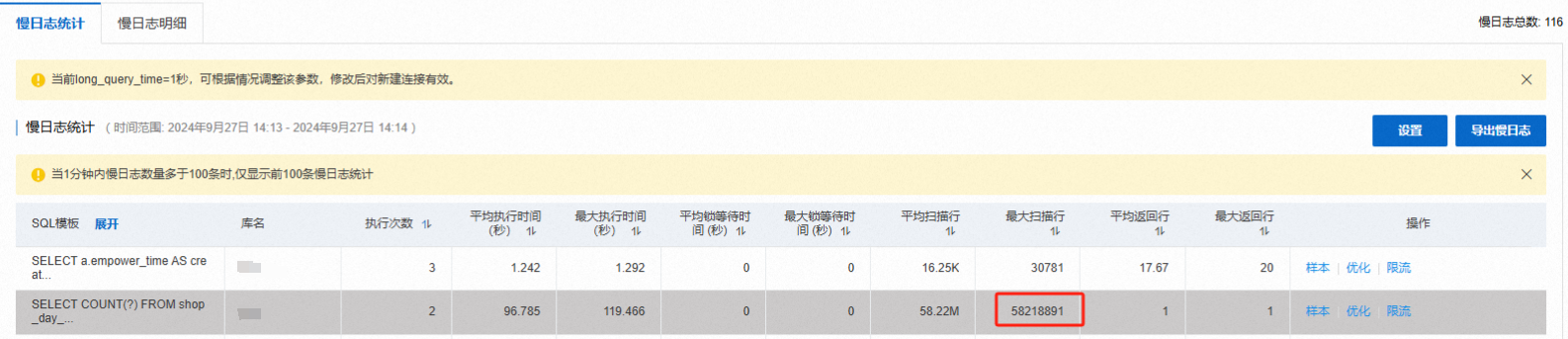
DBA同事在钉钉发了两张截图,作为“始作俑者”的我很心虚,因为刚才是我在管理后台查询数据,结果很久都没出来,并且用多个维度查了N次
问题分析
这是当天上线的功能,完事我立马锁定SQL然后开启排查
# 原SQL,此为分页接口中count部分
SELECT
COUNT( 1 )
FROM
shop_day_statistics a
LEFT JOIN (
SELECT
shop_id shop_id,
statistics_time,
merchant_id,
GROUP_CONCAT( CONCAT_ws( '-', service_id, service_name ) SEPARATOR ',' ) AS service_name,
sum( profit_amount ) profit_amount
FROM
service_day_statistics
GROUP BY
shop_id,
statistics_time
) s ON s.shop_id = a.shop_id
AND a.statistics_time = s.statistics_time
WHERE
a.statistics_time BETWEEN '2023-09-05 00:00:00.0'
AND '2024-10-22 00:00:00.0'
AND a.shop_id = 999999;
# SQL解释
此SQL中有两张表:shop_day_statistics(5800W)、service_day_statistics(30多万)
下面将用A表来替代shop_day_statistics,B表来替代service_day_statistics
A表与B表的关系是一对多,因业务的需要,故之前在一条SQL上查询得出
表结构:
DROP TABLE IF EXISTS `shop_day_statistics`;
CREATE TABLE `shop_day_statistics` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'id',
`statistics_time` date NOT NULL COMMENT '统计日期',
`group_id` bigint NULL DEFAULT NULL COMMENT '代理商ID',
`group_name` varchar(70) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '代理商名称',
`shop_id` bigint NULL DEFAULT NULL COMMENT '门店ID',
`shop_name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '门店名称',
`merchant_id` bigint NULL DEFAULT NULL COMMENT '商户ID',
`merchant_name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '商户名称',
`employee_id` bigint NULL DEFAULT NULL COMMENT '员工ID',
`employee_name` varchar(45) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '员工名称',
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_groupid_time`(`group_id` ASC, `statistics_time` ASC) USING BTREE,
INDEX `idx_merchantid_time`(`merchant_id` ASC, `statistics_time` ASC) USING BTREE,
INDEX `idx_statistics_time`(`statistics_time` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '门店日收益统计' ROW_FORMAT = DYNAMIC;
DROP TABLE IF EXISTS `service_day_statistics`;
CREATE TABLE `service_day_statistics` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'id',
`statistics_time` date NOT NULL COMMENT '统计日期',
`shop_id` bigint NULL DEFAULT NULL COMMENT '门店ID',
`shop_name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '门店名称',
`merchant_id` bigint NULL DEFAULT NULL COMMENT '商户ID',
`merchant_name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '商户名称',
`service_id` bigint NULL DEFAULT NULL COMMENT '服务商id',
`service_name` varchar(45) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '服务商名称',
`profit_amount` bigint NULL DEFAULT NULL COMMENT '服务商收益金额',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '服务商日收益统计' ROW_FORMAT = DYNAMIC;
SQL解析
 从上图可以了解到几个点
从上图可以了解到几个点
-
内层的联表是ALL,也很慢,虽然只有三十多万数据,时间也去到了一秒 -
外层A表是ALL,全表扫描非常慢
依次改造
-
子查询中是没有带任何条件的,故在B表中新增两个参数:group_id,group_name,并为A B表关联的字段增加索引,在后续查询中将外层的条件(门店商户代理商ID)尽可能的加到子查询中,这样能直接命中索引,无需对B进行全表扫描 -
外层A表根据shop_id、statistics_time建立联合索引(shop_id必须放前面,区分度更加高)
改造后SQL及其执行计划
SELECT
COUNT( 1 )
FROM
shop_day_statistics a
LEFT JOIN (
SELECT
shop_id shop_id,
statistics_time,
merchant_id,
GROUP_CONCAT( CONCAT_ws( '-', service_id, service_name ) SEPARATOR ',' ) AS service_name,
sum( profit_amount ) profit_amount
FROM
service_day_statistics
WHERE
statistics_time BETWEEN '2023-09-05 00:00:00.0'
AND '2024-10-22 00:00:00.0'
AND shop_id = 99999
GROUP BY
shop_id,
statistics_time
) s ON s.shop_id = a.shop_id
AND a.statistics_time = s.statistics_time
WHERE
a.statistics_time BETWEEN '2023-09-05 00:00:00.0'
AND '2024-10-22 00:00:00.0'
AND a.shop_id = 99999;

到这个时候就爽了吗,从执行计划上看确实如此,但是我们忽视了这个功能是在web页面上操作的,而操作员可以任何额外条件都不输(只有时间),那执行计划又将非常难看
前端限制
限制管理后台使用人员的操作来达到我们预期的执行计划
-
默认任何额外条件不输入时仅允许7天跨度查询 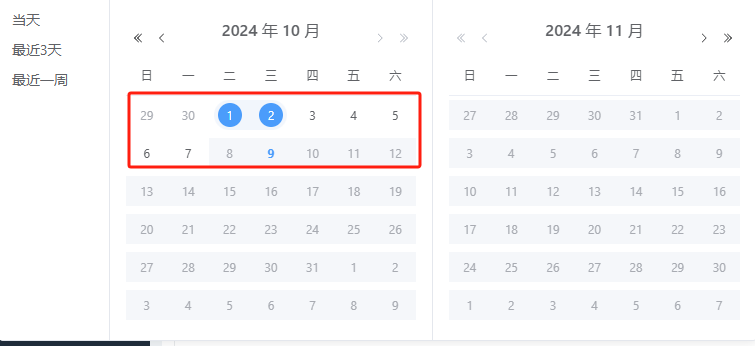
-
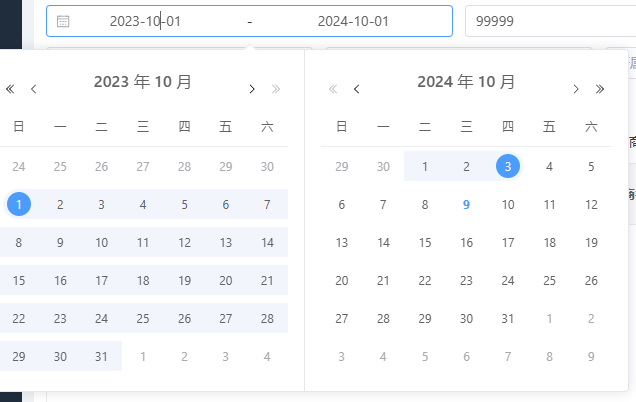
输入代理商/门店/商户ID(这几个字段都与统计时间有做联合索引)后,时间将会允许拉长跨度进行查询
写到最后
对于一个SQL的优化我感触比较深的是:不能仅从SQL本身去进行优化,而需要结合具体的业务进行权衡从而选择一个合适的方案进行优化,目前项目也到高速上升期,出现了很多大表,未来系统将会有更多的问题,当然这即是问题也是挑战,加油!!!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。


评论(0)